Aunque en ocasiones se utilizan como sinónimos, no son lo mismo.
- Modelos de lenguaje: Están entrenados para comprender y generar texto de forma que sea coherente para un humano. Se basan en el procesamiento del lenguaje natural (PLN) que es una rama de la IA que se encarga de que las computadoras entiendan, interpreten y generen lenguaje humano de texto y voz. Se emplean para responder preguntas, resumir textos y el reconocimiento y generación de voz. Para ello, los ordenadores utilizan algoritmos, técnicas de aprendizaje automático y redes neuronales profundas que permiten procesar grandes cantidades de texto e identificar patrones en el lenguaje humano. El PLN se basa en que las palabras de un idioma no se utilizan de forma aleatoria, sino que se relacionan de una forma predecible. Por ejemplo, si se introduce la expresión “El perro está ladrando porque ha visto a…”, el modelo determina que es más probable que la oración continúe con “un gato” o “un extraño” que con “una mesa” o “un periódico”.
Se incluyen en este apartado los modelos conversacionales que son los creados para mantener diálogos con humanos, entendiendo lo que se les dice y respondiendo de una forma coherente. Estos modelos han sido diseñados para comprender el lenguaje natural, interpretar las intenciones del usuario y generar respuestas relevantes y lógicas. Se utilizan como asistentes virtuales, chatbots e interfaces de voz. Están basados en modelos de lenguaje grandes (LLM) entrenados con grandes cantidades de texto. Se utilizan en una amplia gama de aplicaciones, como asistentes virtuales, chatbots, sistemas de atención al cliente automatizados e interfaces de voz. Algunos modelos conversacionales son ChatGPT, Gemini, Copilot o Claude.
Uno de los modelos de lenguaje más conocidos es Generative Pretrained Transformer (GPT) que es un sistema de procesamiento de lenguaje natural diseñado por OpenAI. Sus siglas significan:
- Generative (Generativo): Hace referencia a su capacidad para generar texto de forma autónoma.
- Pre-trained (Preentrenado): Antes de ser utilizado, el modelo ha sido entrenado con grandes cantidades de texto para comprender el lenguaje y sus estructuras gramaticales.
- Transformer: Es una arquitectura de inteligencia artificial especialmente eficaz para el procesamiento de lenguaje natural desarrollada originalmente por investigadores de Google y adoptada ampliamente por toda la industria.
No se debe confundir un modelo GPT de procesamiento del lenguaje natural con ChatGPT que es un modelo conversacional.
- Modelo de texto: Es un concepto más ambiguo y menos preciso. Se refiere a modelos que procesan texto, como los modelos de lenguaje, pero además incluyen otros más específicos como clasificadores —email spam/no spam—, análisis de sentimientos —opinión positiva, negativa o neutra—, detectores de idioma —inglés / español / francés—, etc. Estos modelos también trabajan con texto, pero su objetivo no es comprender los patrones del lenguaje humano, sino realizar una tarea concreta, como clasificar, detectar o puntuar.
En resumen, todos los modelos de lenguaje son modelos de texto, pero no todos los modelos de texto son modelos de lenguaje.
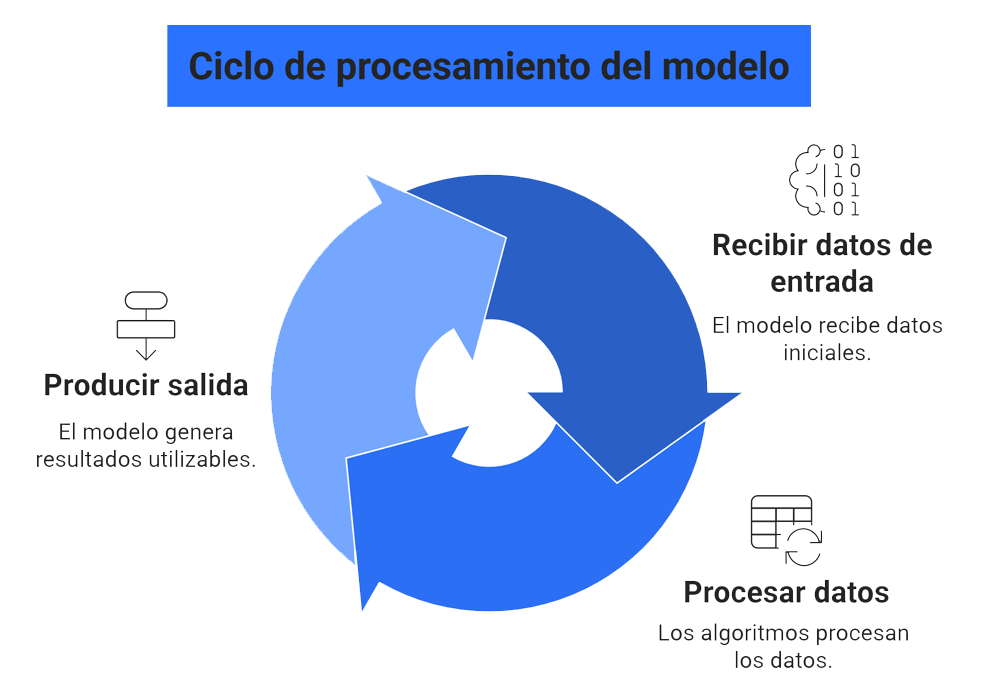 Ciclo de procesamiento (Imagen generada con Napkin AI, 2026)
Ciclo de procesamiento (Imagen generada con Napkin AI, 2026)