Generar una locución con ElevenLabs
Una de las aplicaciones más interesantes de la IA generativa aplicada a la docencia es la conversión de texto a voz (text-to-speech), capaz de transformar cualquier texto en una locución.
En este ejemplo, se utiliza la versión gratuita de la aplicación ElevenLabs disponible en https://elevenlabs.io/ El plan gratuito ofrece 10.000 caracteres —equivalente a créditos— al mes, lo que equivale a unos 10 minutos de audio.
En ElevenLabs, para crear una locución hay que acceder al menú “Text to Speech” y en el apartado “Settings” (columna derecha) configurar los siguientes parámetros:
- Voice: Seleccionar la voz del locutor. Junto al nombre del locutor aparece una breve descripción del tipo de voz y el botón “Play Preview” permite escucharla. Se puede elegir entre una amplia variedad de voces predeterminadas en diferentes idiomas y con distintos acentos, géneros y estilos.
- Model: Los modelos son las versiones o tipos de IA que se utilizan para generar la voz. Cada modelo tiene características y capacidades distintas en cuanto a realismo, expresividad, velocidad e idioma.
- Speed: Controla la velocidad a la que se reproduce la voz. El valor predeterminado es 1.0 que se corresponde con la velocidad normal. Valores superiores incrementan la velocidad e inferiores la reducen.
- Stability: La estabilidad controla cuánto varía la entonación y la emoción de la voz. El valor predeterminado es 50%. Un valor alto, por ejemplo, 80%-90%, hace que la voz suene más constante, monótona, predecible y sin grandes cambios en su tono o emoción. Es ideal para lecturas formales, narraciones educativas o textos largos donde se busca uniformidad. Un valor bajo, por ejemplo, 20%-30%, permite que la voz incluya más variaciones naturales, con pausas, énfasis y emociones más marcadas, pero también puede generar inconsistencias. Es adecuada para diálogos, interpretaciones o contenido más expresivo.
- Similarity: Este ajuste determina cuánto se parece la voz generada a la del modelo seleccionado. Valores altos hacen que se parezca mucho a la voz de referencia, mientras que valores bajos introducen más variaciones y reducen la similitud.
- Style exaggeration: Este ajuste te permite elegir entre velocidad/estabilidad y expresividad. El valor por defecto es 0.0 y produce un habla estable y neutra. Valores altos se usan cuando se desea que el estilo o la emoción del habla sea más exagerado o dramático. El inconveniente es que puede introducir inestabilidad en el audio, lo que significa que la voz podría sonar distorsionada, robótica o con errores.
- Speaker boost: Al activarlo, la voz generada se parece más a la voz de la muestra original. Lograr esa mayor similitud requiere más procesamiento por parte del sistema, lo que reduce la velocidad de generación. Es un compromiso entre calidad (similitud) y eficiencia (velocidad).
Los parámetros seleccionados en este ejemplo son: Voice: Martin Osborne; Model: Eleven Multilingual v2; Speed: 1.0; Stability: 40%; Style exaggeration: none; Speaker boost: activado.
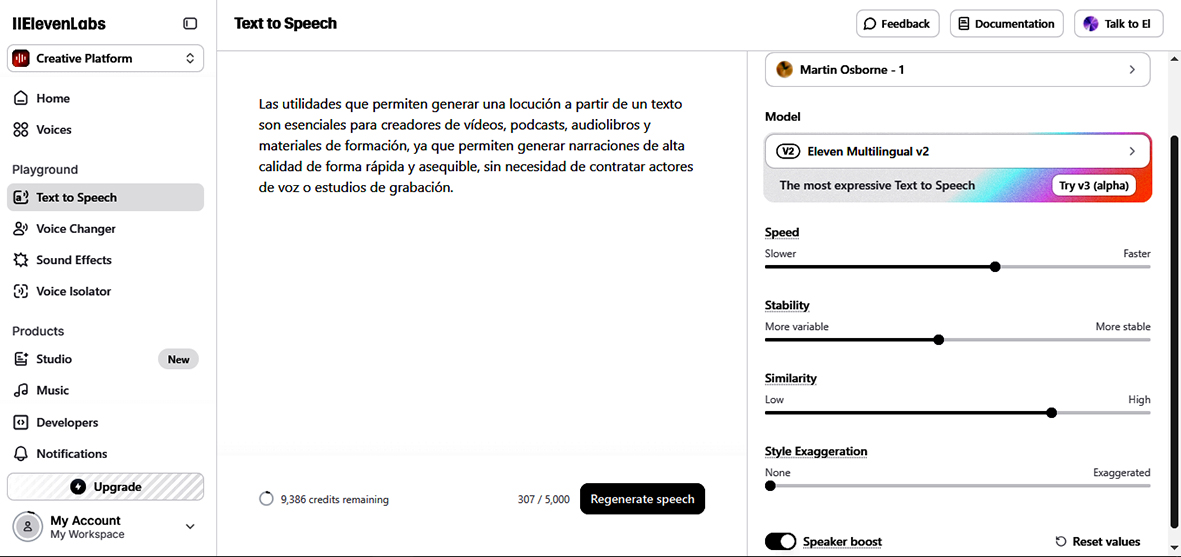
Es recomendable experimentar con los diferentes valores de los parámetros hasta encontrar la configuración que mejor se adapte a las necesidades del usuario.
A continuación, hay que indicar el texto del que se desea generar la locución y pulsar el botón “Generate Speech”. El resultado se puede descargar en formato mp3 o generar un vídeo con el texto (subtítulos) en formato mp4.
Texto de la locución: Las utilidades que permiten generar una locución a partir de un texto son esenciales para creadores de vídeos, podcasts, audiolibros y materiales de formación, ya que permiten generar narraciones de alta calidad de forma rápida y asequible, sin necesidad de contratar actores de voz o estudios de grabación.
Audio generado (ElevenLabs):
Vídeo generado (ElevenLabs):
Con ElevenLabs es sencillo generar una locución en diferentes idiomas.